栈和队列
栈和队列都是动态集合,在栈(stack)中,被删除的是最近插入的元素:栈实现的是一种后进先出(last-in,first-out,LIFO)策略
在队列(queue)中,被删去的总是在集合中存在时间最长的那个元素。实现的是先进先出(first-in,first-out,FIFO)策略
在队列(queue)中,被删去的总是在集合中存在时间最长的那个元素。实现的是先进先出(first-in,first-out,FIFO)策略
栈
栈上的INSERT操作为压栈(PUSH),DELETE操作为出栈(POP).可以用一个数组S[1...N]来实现一个最多容纳n个元素的栈,该数组有一个属性S.top,指向最新插入的元素。栈中包含的元素为S[1...S.top],其中S[1]是栈底元素,S[S.top]为栈顶元素
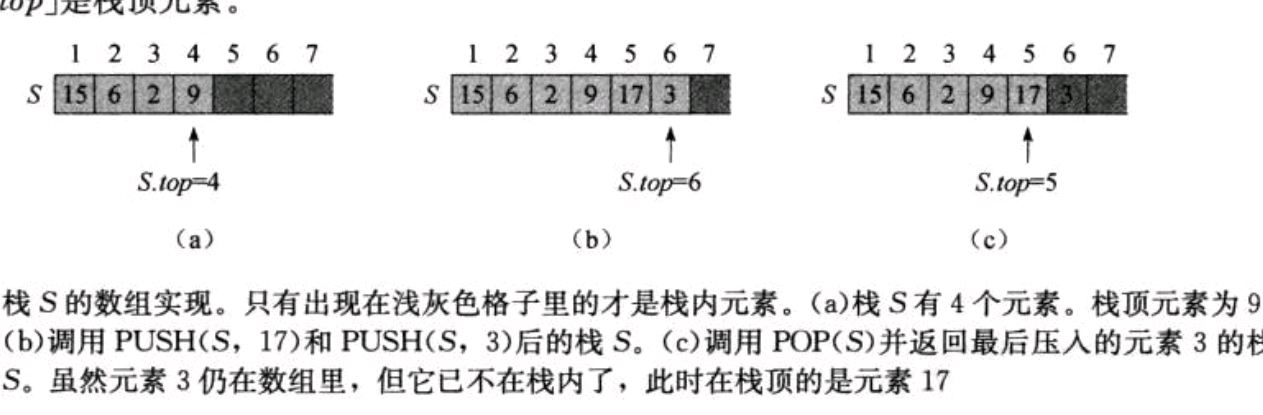 当S.top=0时,栈中不包含任何元素,即栈是空(empty)的。如果试图对一个空栈进行弹出操作,则称为下溢(underflow),如果S.top超过了n,则称为上溢(overflow)
当S.top=0时,栈中不包含任何元素,即栈是空(empty)的。如果试图对一个空栈进行弹出操作,则称为下溢(underflow),如果S.top超过了n,则称为上溢(overflow)
在下面伪代码中不考虑栈的上溢问题:
当S.top=0时,栈中不包含任何元素,即栈是空(empty)的。如果试图对一个空栈进行弹出操作,则称为下溢(underflow),如果S.top超过了n,则称为上溢(overflow)
EMPTY:
STACK-EMPTY(S)
1 if S.top==02return TRUE 3 else return FALSE
PUSH(S,x)
1 S.top = S.top + 12 S[S.top] = x
Pop(S)
1 if Stack-EMPTY(S)2error "underflow" 3 else S.top = S.top - 14 return (S[S.top + 1])
三种操作的时间复杂度都为O(1)
扩展:
- 说明如何在一个数组A[1...n]中实现两个栈,使得当两个栈的元素个数之和为不为n时,两者都不会发生上溢,要求PUSH和POP操作的运行时间为O(1)
对一个数组头和尾分别指定为栈底,两个栈相向增长,就同时满足以上两个条件
-
说明如何用两个栈实现一个队列,并分析相关队列操作的运行时间。
栈是采用后进先出的策略,也就是说栈最后弹出栈的是最开始进栈的那一个,所以可以用两次压栈的方式:对第一次进栈序列的所有元素依次出栈在进行进栈,从而得到栈出栈序列的翻转,这样我们就得到一个队列的序列。
链表
链表(Linked List), 数组的线性顺序是由数组下标决定的,然而与数组不同的是,链表的顺序是由各个对象里的指针决定的。
双向链表
双向链表(doubly linked list)L的每一个元素都是一个对象,每个对象有一个关键字key和两个指针:next和prev。对象中还可以包含其他的辅助数据(或称卫星数据)。设x为链表的一个元素,x.next指向它在链表中的后继元素,x.prev指向它在链表中的前驱元素。
- 如果x.prev=NIL,则元素没有前驱,因此x是链表的第一个元素,即链表的头(head).
- 如果x.next=NIL,则元素没有后继,因此x是链表的最后一个元素.
- 如果L.head=NIL,则链表为空
循环链表(circular list)
表头元素的prev指针指向表尾元素,而表尾元素的next指针指向表头元素。这时链表相当于一个环。
链表的操作:
-
链表的搜索:用于查找链表L中第一个关键字为k的元素,并返回指向该元素的指针。如果链表没有关键字为k的对象,则返回NIL
LIST-SEARCH(L,k)
1 x=L.head
2 while x!=NIL and x.key!=k
3x = x.next
4 return x
要搜索一个有n个对象的链表,过程LIST-SEARCH在最坏情况下的运行时间为 Θ(n),因为可能需要搜索整个链表。 -
链表的插入:将x插入到链表的前端
LIST-INSERT(L,x)
1 x.next=L.head
2 if L.head!=NIL
3L.head.prev=x
4 L.head=x
5 x.prev=NIL在一个含n个元素的链表上执行LIST-INSERT的运行时间是Ο(1) -
链表的删除:
LIST-DELETE(L,x)
1 if x.prev!=NIL
2x.prev.next=x.next
3 else L.head=x.next
4 if x.next!=NIL
5x.next.prev=x.prev LIST-IDELETE的运行时间是Ο(1),但如果要删除具有给定关键字的元素,则再最坏的情况下为θ(n),因为需要调用LIST-SEARCH找到该元素。
哨兵
如果可以忽略表头和表尾的边界条件,则LIST-DELETE的代码可以更简单些。哨兵是一个哑对象,其作用是简化边界条件的处理。例如:假设在链表L中设置一个对象L.nil,该对象代表NIL,但也具有和其他对象相同的各个属性,对于链表代码中出现的每一处对NIL的引用,都代之以对哨兵L.nil的引用。如下图,这样的调整将一个常规的双向链表转变为一个有哨兵的双向循环链表(circular,doubly linked list with sentinel),哨兵L.nil位于表头和表尾之间。
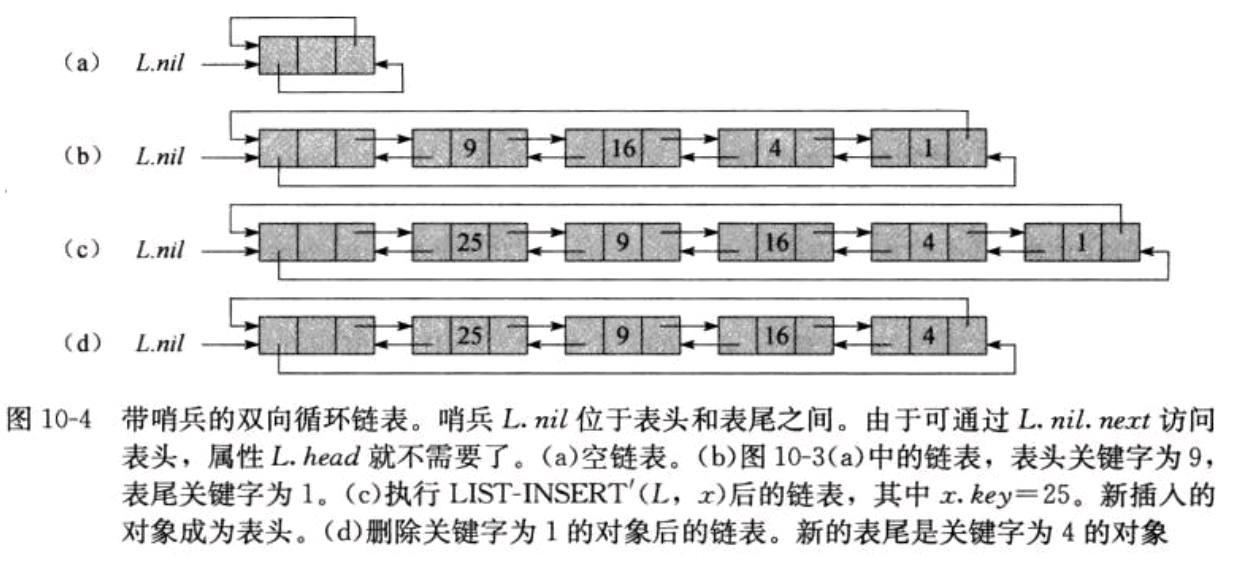
-
属性L.nil.next指向表头
属性L.nil.prev指向表尾 -
表头的prev和表尾的next指向L.nil
-
LIST-SEARCH的代码基本不变,
LIST-SEARCH`(L,k)
1 x=L.nil.next
2 while x!=L.nil and x.key!=k
3x = x.next
4 return x -
插入:
LIST-INSERT(L,x)
1 x.next=L.il.next
2 L.nil.next.prev=x
3 L.nil.next=x
4 x.prev=L.nil -
删除:
LIST-DELETE`(L,x)
1 x.prev.next=x.next
2 x.next.prev=x.prev
扩展
-
单链表上的动态集合操作INSERT能否在Ο(1)时间内实现?DELETE操作
方法一(尾插法):用一个指针tail指向表尾结点,其添加和删除都在表尾进行.
1 x.next=tail
2 tail=x方法二(头插法):对表头前进行插入和删除,为了方便,采用带哨兵的单链表1 x.next=L.nil.next
2 L.nil.next=x -
用一个单链表L实现一个栈,要求操作PUSH和POP的运行时间为Ο(1)
采用头插法,PUSH就能达到Ο(1)
出栈:
Stack-POP(S)
1 if L.nil.next != L.nil
2x=L.nil.next
3L.nil.next=x.next
4return x -
如前所述,LIST-SEARCH`过程中的每一次循环迭代都需要两个测试:一是检查x!=L.nil,另一个是检查x.key!=k.试说明如何在每次迭代中省略对x.nil的检查
LIST-SEARCH(L,k)
1 x=L.nil.next
2 L.nil.key=k
3 while x.key!=k
4x=x.next
5 return x -
动态集合操作UNION以两个不相交的集合S1和S2作为输入,并返回集合S=S1∪S2,包含S1和S2的所有元素。该操作通常会破坏集合S1和S2.试说明如何选用一种合适的表类数据结构,来支持Ο(1)时间的UNION操作。
采用链表的方式,只需要把S1的表尾与S2的表头拼接起来,时间上为Ο(1)
-
给出一个θ(n)时间的非递归过程,实现一个含n个元素的单链表逆转。要求除存储链表本身所需的空间外,该过程只能使用固定的大小的存储空间
LIST-REVERSION(L)
1 new S.nil
2 x=L.nil.next
3 whie x!=L.nil
4node=x.next
5x.next=S.nil.next
6S.nil.next=x
7x=node
8 L.nil=S.nil