- 已经知道两个链表A和B分别表示两个集合,其元素递增排列。请设计算法求出两个集合A与B的交集
List-Intersection(L1,L2)
1 new tail=L3.nil
2 p1=L1.nil.next
3 p2=L2.nil.next
4 while p1!=L1.nil and p2!=L2.nil
5 if p1.key < p2.key
6p1=p1.next
7 else if p2.key < p1.key
8p2=p2.next
9 else
10temp=p1.next
11p1=tail.next
12tail.next=p1
13tail=tail.next
14p2=p2.next
15p1=temp
-
已经知道两个链表A和B分别表示两个集合,其元素递增排列。请设计算法求出两个集合A与B的差集(即仅由在A出现而不再B出现的元素所构成的集合),并以同样的存储形式存储,同时返回元素的个数。
Linked_Difference(L1,L2,count)
1 p1=L1.nil.next
2 p2=L2.nil.next
3 Tail=L1.nil
4 length=0
5 while p2!=L2.nil and p1!=L1.nil
6if p1.key==Tail.key
7Tail.next=p1.next
8if p1.key< p2.key
9p1=p1.next
10Tail=Tail.next
11length = length + 1
12else if p1.key> p2.key
13p2=p2.next
14else
15p1=p1.next
16Tail.next=p1
17count=length
18 return L1算法流程:初始化:让表尾指针引用L1的哨兵循环合并:- 当p1.key=Tail.key时,证明现在已经扫描过的LA中出现重复数据,把重复的结点删去,p1指向后继结点
- 当p1.key< p2.ke时,证明p1不在LB中出现,只需要让p1指向下一个结点和让记录当前扫描过LA序列中p1的前驱结点
- 当p2.key< p1.key时,证明p1不在LB中出现,让p2指向它的后继再次进行比较
- 当p1.key=p2.key时,证明p1所指向的结点出现在LB中,需要把这个结点删除,Tail的next指向p1的后继,同时让p1指向它的后继结点进行下一轮的判断,
循环结束:p1的序列已经遍历完或p2遍历完,无论哪种都已经完成LA-LB差集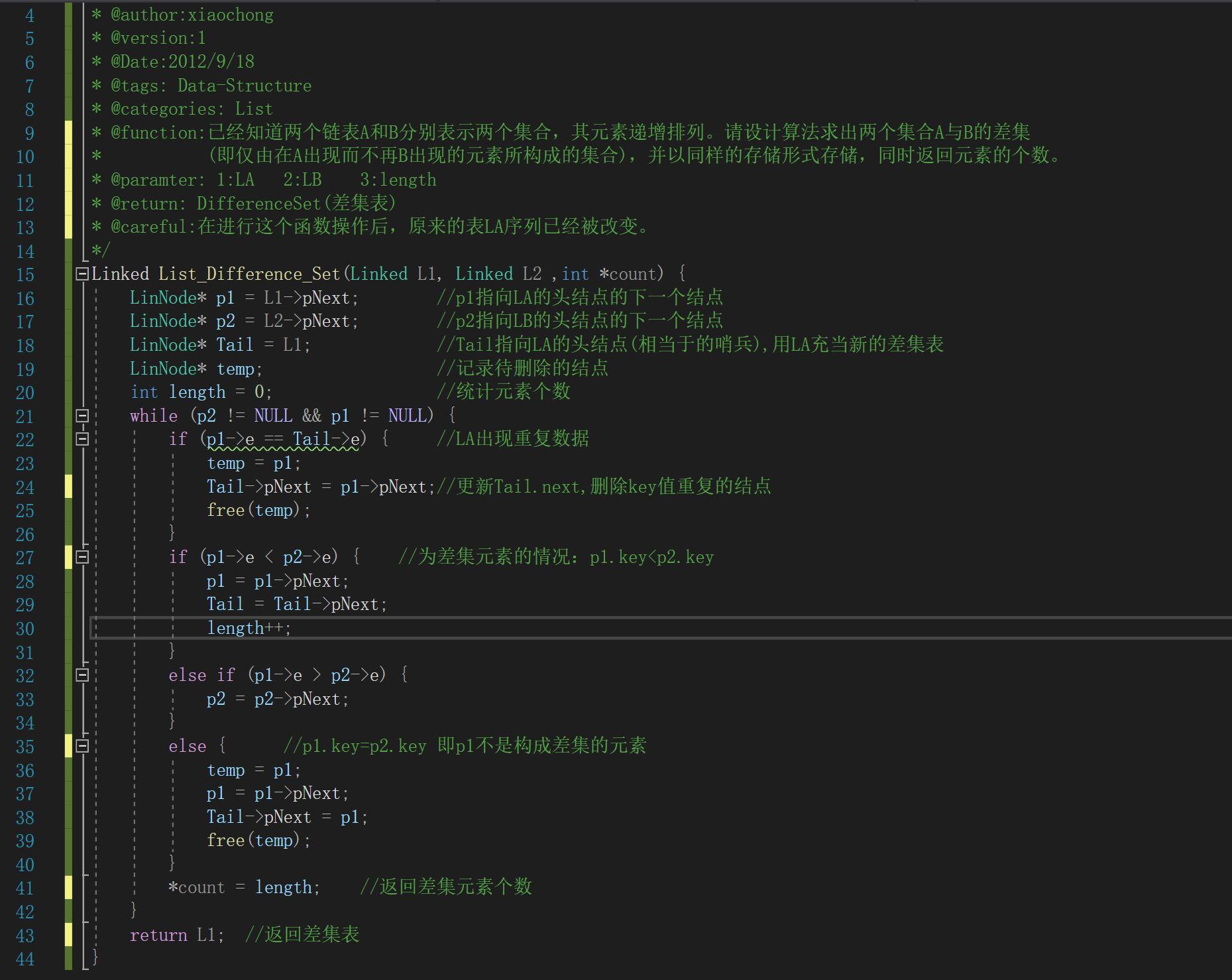
-
设计算法将一个带头结点的单链表A分解为两个具有相同结构的链表B和C,其中B表的结点为A表中值小于零的结点,而C表的结点为A表中值大于零的结点(链表A中的元素为非零的整数,要求B、C表1利用表A的结点)
List-Split(L1,L2)
1 p1=L1.nil.next
2 new n2=L2.nil
3 L3=L1.nil
4 while p1!=L1.nil
5if p1.key<=0< view>
6L3=L3.next
7p1=p1.next
8else
9temp=p1.next
10p1.next=p2.next
11p2.next=p1
12p2=p2.next
13L3.next=temp
14p1=temp
链表的算法设计1-2
Author: xiao chong
Permalink: http://example.com/2021/09/18/list1-3/
License: Copyright (c) 2019 CC-BY-NC-4.0 LICENSE
Slogan: Do you believe in DESTINY?